
About Black Forest Labs Launch

We are thrilled to announce the launch of Black Forest Labs. As a key player in the generative AI research community, they aim to develop and advance state-of-the-art generative deep learning models for media, including images and videos. They aim to push the boundaries of creativity, efficiency, and diversity. By making their models accessible to a wide audience, they strive to bring the benefits of generative AI to everyone, educate the public, and enhance trust in the safety of these models. Their goal is to establish the industry standard for generative media, starting with the release of the FLUX.1 suite of models that redefine text-to-image synthesis.
The Black Forest Team
The team at Black Forest Labs consists of distinguished AI researchers and engineers with a proven track record in developing foundational generative AI models across academic, industrial, and open-source environments. Their innovations include VQGAN, Latent Diffusion, Stable Diffusion models (Stable Diffusion XL, Stable Video Diffusion, Rectified Flow Transformers), and Adversarial Diffusion Distillation for ultra-fast, real-time image synthesis. They believe that widely accessible models foster innovation, collaboration, and transparency, which are essential for trust and broad adoption.
Flux.1 Model Family
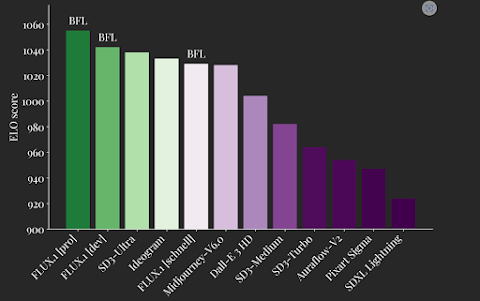
They are proud to release the FLUX.1 suite of text-to-image models, setting a new benchmark in image detail, prompt adherence, style diversity, and scene complexity. FLUX.1 comes in three variants:
- FLUX.1 [pro]: Their top-performing model for state-of-the-art image generation. Available via API, Replicate, and fal.ai, with dedicated enterprise solutions.
- FLUX.1 [dev]: An open-weight, guidance-distilled model for non-commercial applications, offering similar quality and efficiency as FLUX.1 [pro]. Available on HuggingFace, Replicate, and fal.ai.
- FLUX.1 [schnell]: Their fastest model for local development and personal use, available under an Apache 2.0 license. Weights are available on Hugging Face, with inference code on GitHub and HuggingFace’s Diffusers.
Technical Advancements
The FLUX.1 models are built on a hybrid architecture of multimodal and parallel diffusion transformer blocks, scaled to 12B parameters. The models leverage flow matching, rotary positional embeddings, and parallel attention layers to enhance performance and hardware efficiency.
Benchmark Achievements
FLUX.1 sets a new standard in image synthesis, surpassing models like Midjourney v6.0, DALL·E 3 (HD), and SD3-Ultra in visual quality, prompt adherence, size/aspect variability, typography, and output diversity. Their models support a range of aspect ratios and resolutions, showcasing improved possibilities compared to current state-of-the-art models.
Code# Install the diffusers package from Hugging Face repository
!pip install git+https://github.com/huggingface/diffusers.git
# Import PyTorch library
import torch
# Import the FluxPipeline class from the diffusers package
from diffusers import FluxPipeline
# Load the pre-trained FluxPipeline model with a specific configuration
pipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-schnell", torch_dtype=torch.bfloat16)
# Enable model CPU offloading to save some VRAM
pipe.enable_model_cpu_offload() #save some VRAM by offloading the model to CPU. Remove this if you have enough GPU power
# Import display function from IPython for displaying images
from IPython.display import display
import torch
# Import the Image class from the PIL library for image manipulation
from PIL import Image
#prompt = "A cat holding a sign that says hello world"
#prompt = "black forest toast spelling out the words 'FLUX DEV', tasty, food photography, dynamic shot"
prompt = "a brown SUV moving car in the forest with the name 'DataEdge' written on it,dynamic shot"
# Generate the image using the pipeline with the specified prompt and settings
image = pipe(
prompt,
guidance_scale=0.0, # Guidance scale for image generation (0 means no guidance)
output_type="pil", # Output type of the generated image (PIL image)
num_inference_steps=4, # Number of inference steps for image generation
max_sequence_length=256, # Maximum sequence length for the prompt
generator=torch.Generator("cpu").manual_seed(0) # Set a seed for reproducibility
).images[0]
# Resize the image
new_size = (800, 800) # Change this to your desired size
resized_image = image.resize(new_size, Image.LANCZOS) # Resize using LANCZOS filter
# Display the resized image
display(resized_image)
#resized_image.save("/content/sample_data/flux-schnell.png")
#resized_image.save("/content/sample_data/blackforest.png")
resized_image.save("/content/sample_data/trainforest.png")